
Correlation (aka correlated subquery) means: a subquery that references columns from the outer query, so it must be re-evaluated for each outer row.
It’s super common for:
- “Pick rows where something exists / doesn’t exist”
- “Compare a row to an aggregate of its group”
- “Top-N per group” (with some variations)
Example tables (with sample data)
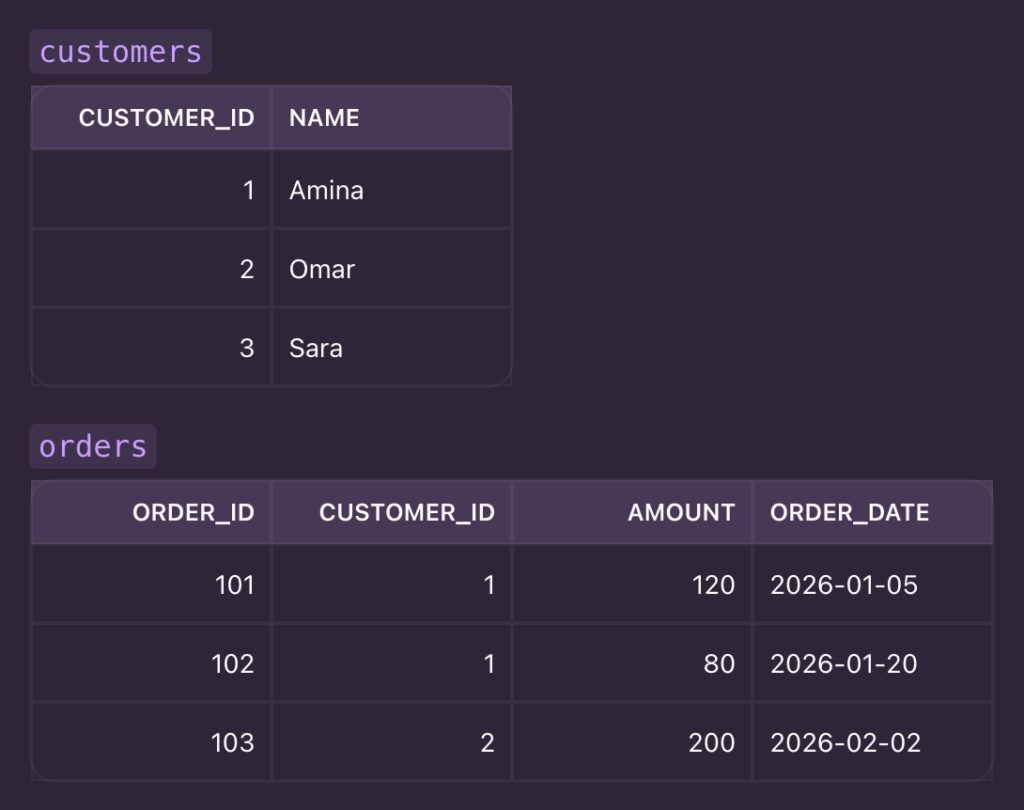
1) Correlated subquery with EXISTS (classic “has related rows”)
Goal
Return customers who have at least one order.
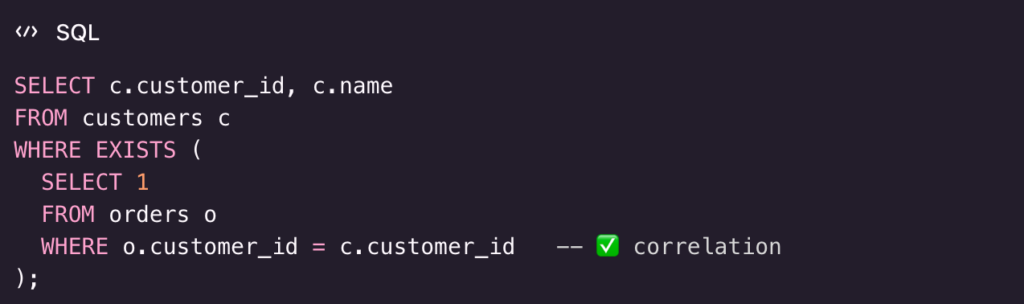
What happens (row-by-row intuition)
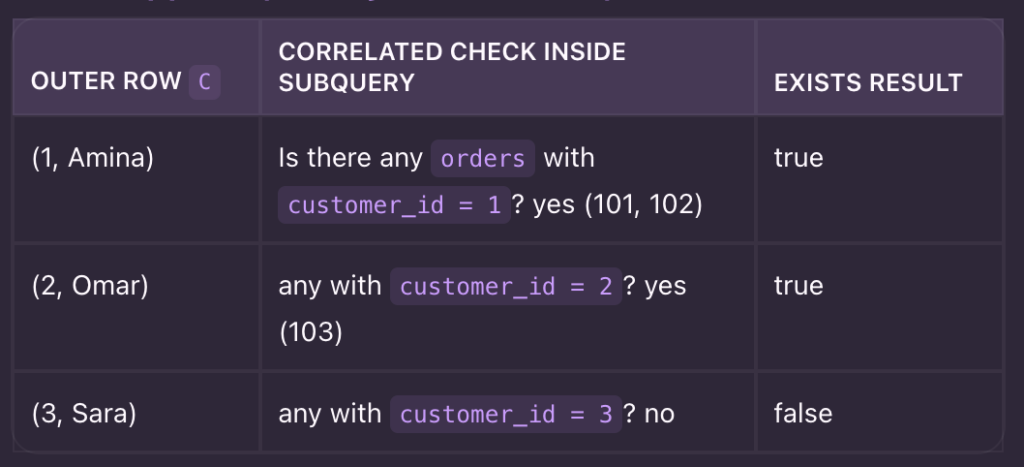
✅ Output: Amina, Omar
2) Correlated subquery with NOT EXISTS (“has no related rows”)
Goal
Return customers with no orders.
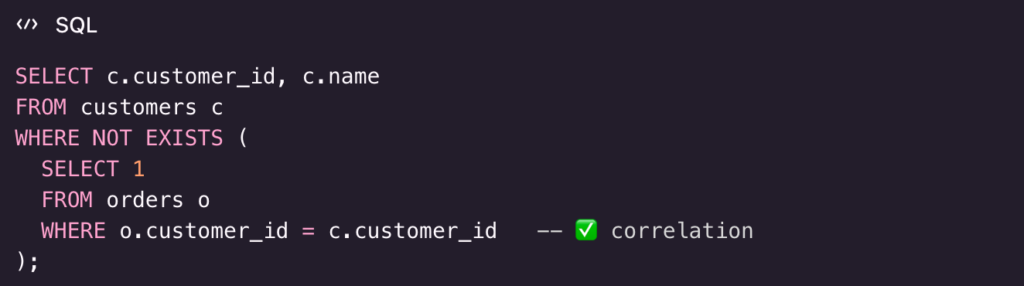
✅ Output: Sara
Tip:
NOT EXISTSis usually safer thanNOT IN (...)when NULLs could appear.
3) Correlated subquery in SELECT (computed per row)
Goal
Show each customer with their total spent.
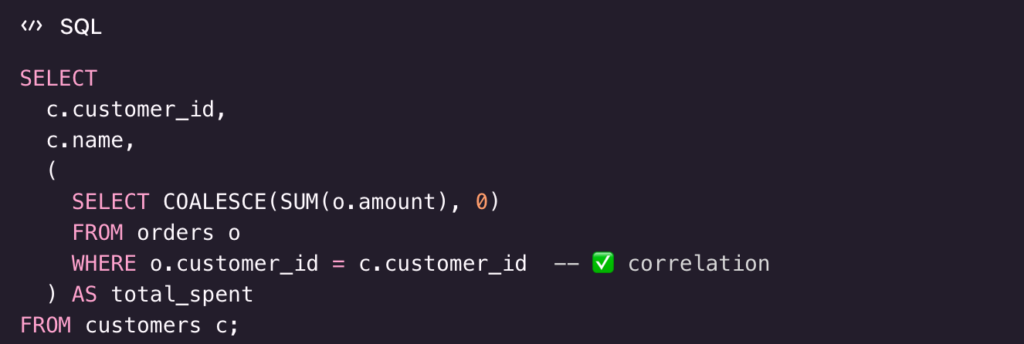
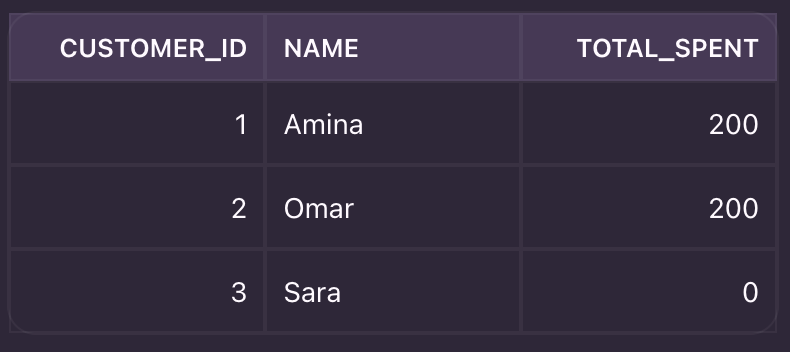
Result
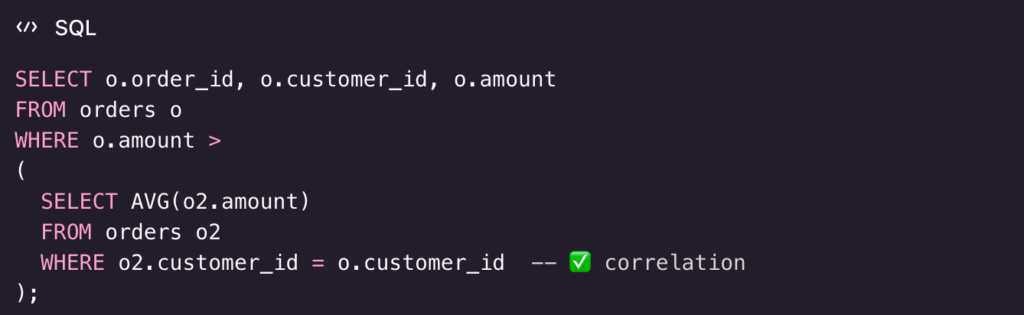
4) Correlated subquery for “greater than group average”
Goal
List orders whose amount is above that customer’s average order amount.
Intuition table
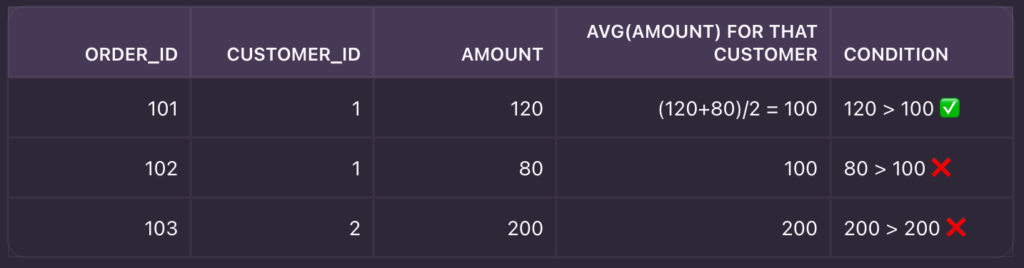
✅ Output: order 101
5) “Latest order per customer” using a correlated subquery
Goal
Return each customer’s most recent order.
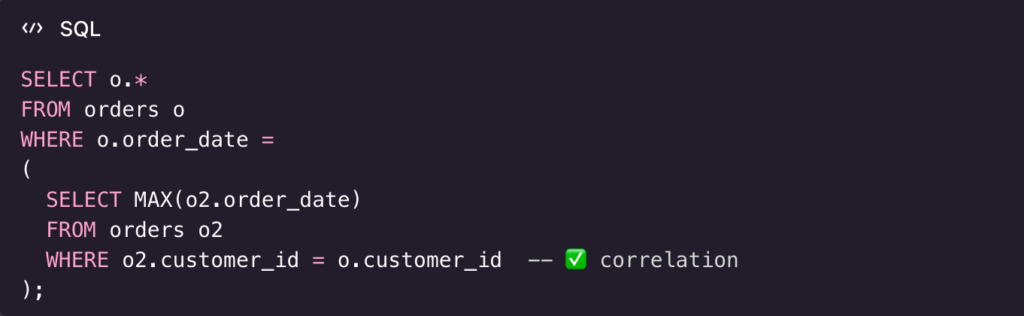
If two orders tie on the same max date, you’ll get both (often OK, sometimes not).
Performance notes (quick but important) ⚙️
- A correlated subquery can run “per row”, but PostgreSQL often optimizes it well (especially
EXISTS). - Indexes matter a lot:
orders(customer_id)orders(customer_id, order_date)for latest-per-customer patterns
